WTIANNS is a form of 'wavetable' synthesis compatible with the TSARA system. I used 'wavetable' in quotes because it is technically not wavetable synthesis by some accounts; WT synthesis implies that many waveforms are stored in memory as a lookup table.
WT synthesis can occur in multiple dimensions, but the memory requirements become very burdensome beyond 3 dimensions. For example, suppose we use length-64 wavetables (which is quite small; the norm is more like 512-4096) using single-precision floating point (32 bits per sample). Suppose we have 16 wavetables per dimension, and have a 2D wavetable. In other words, the dimensions X and Y index uniquely within the wavetable. That would be 16x16x64=16384 samples, which means 524288 bits=512 kb.
Adding a third dimension, we are already at 512x16=16384 kb, or 16 mb.
Adding a fourth dimension, this wavetable would be 16x16 mb = 256 mb. That is a lot of space for a single, low resolution 4D wavetable, when you consider that you probably want a bunch of different wavetables in the synth.
So, WTIANNS takes another approach to optimize this storage problem away, while acheiving the same effect as having a high dimensional wavetable (and we're talking on the order of 10 dimensions, could be more but it becomes unwieldy). WTIANNS uses timbre analysis of an audio file–in particular, the Bark-frequency spectrum of the audio over time. The analysis exported includes this compressed representation of the audio, along with a single-cycle spectrum of the audio over time.
Now, the analysis file from the TSARA application can be thought of as pairs of [timbreContent, singleCycleWaveform]. These pairs are then fed into a neural network, for now a multiplayer perceptron, which learns a continuous mapping from the input (timbreContent) to the output (singleCycleWaveform).
Once the network is trained, its parameters can be saved for simple use at a later time. The user can import one of these networks into WTIANNS, and set the knobs however they choose to continuously navigate through the timbre space.
At least, that is the simplicity of the interface implied in its current form, which is a Pd external. I plan to expand this idea for&beyond my dissertation to be a full-fledged plugin.
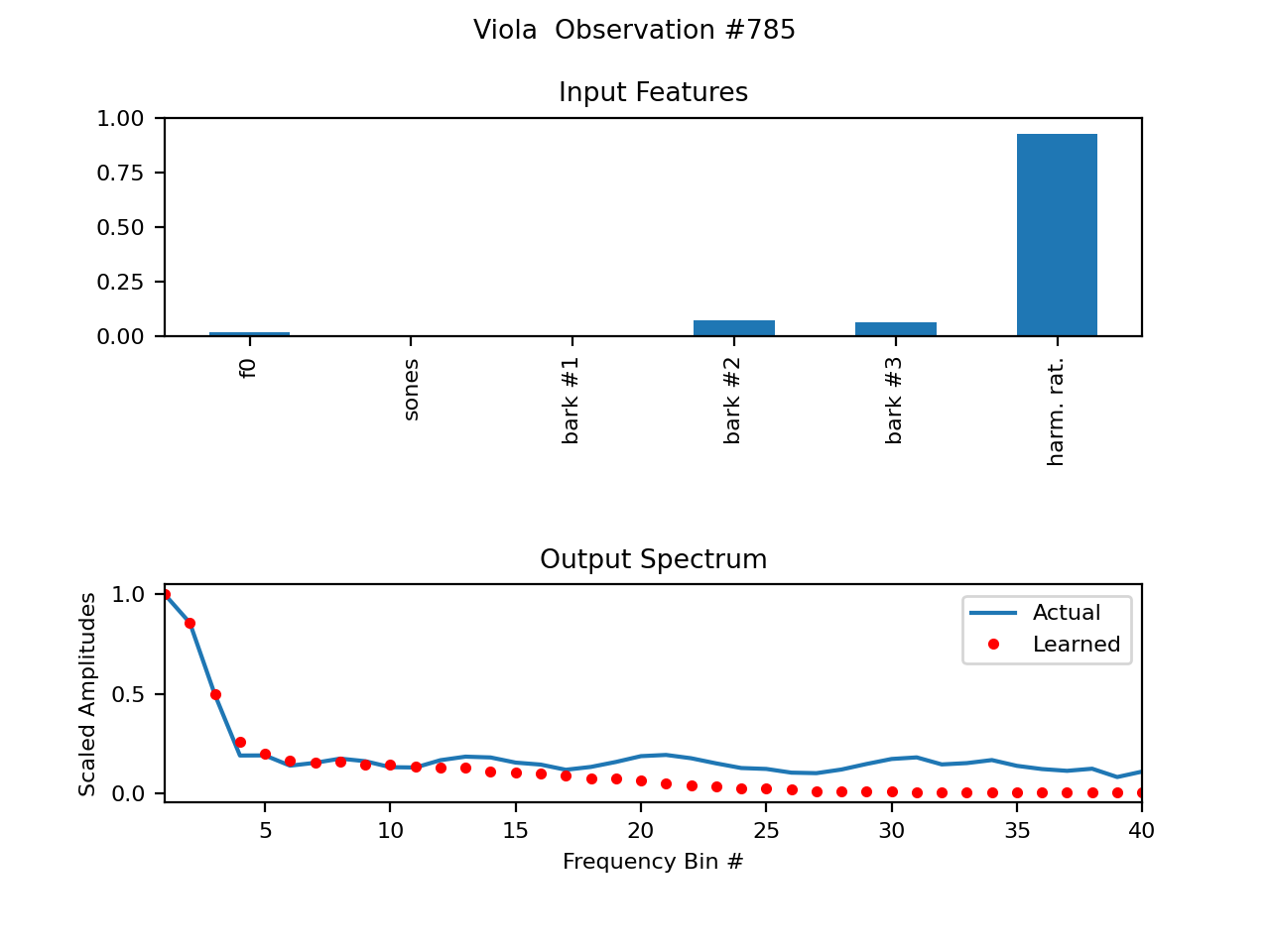
Below are some plots of some example spectral wavetables. The (first few) parameters are shown on top. f0, or fundamental frequency, simply looks so small because it is normalized as 0Hz->0, Nyquist->1, and most fundamental frequencies are much closer to 0. The differences between the data samples from the recording (piano) and trained imitation are shown below.
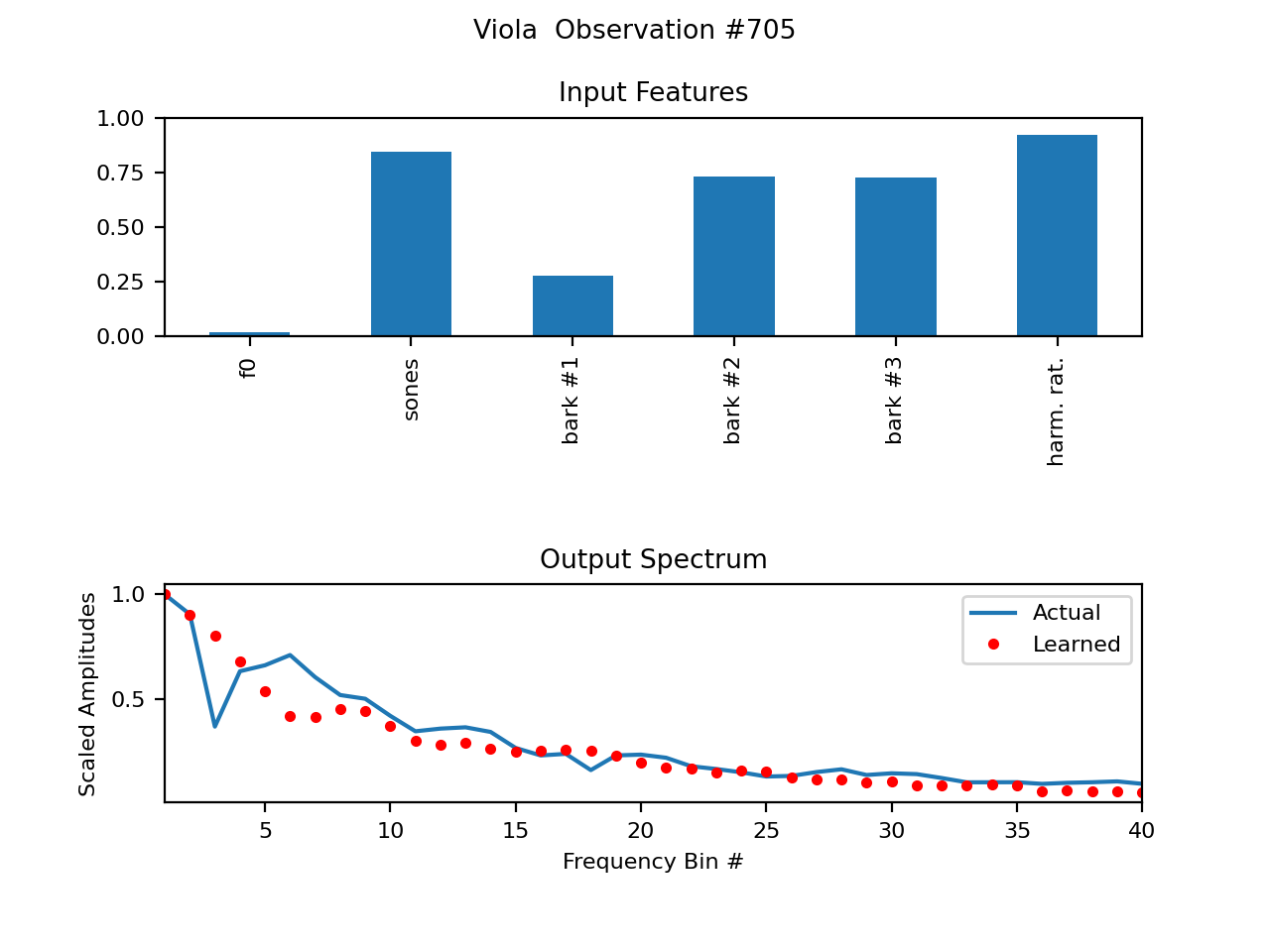
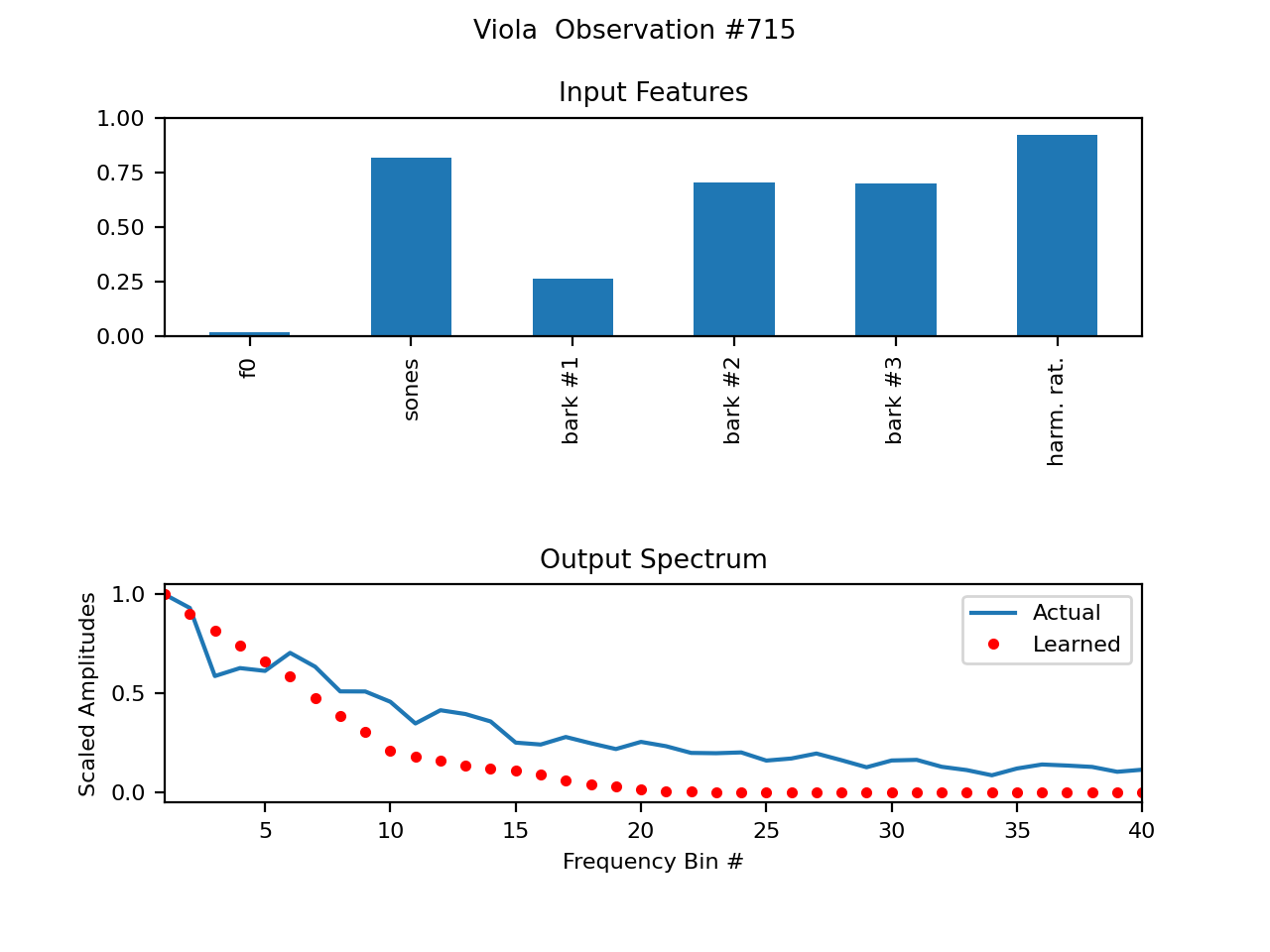
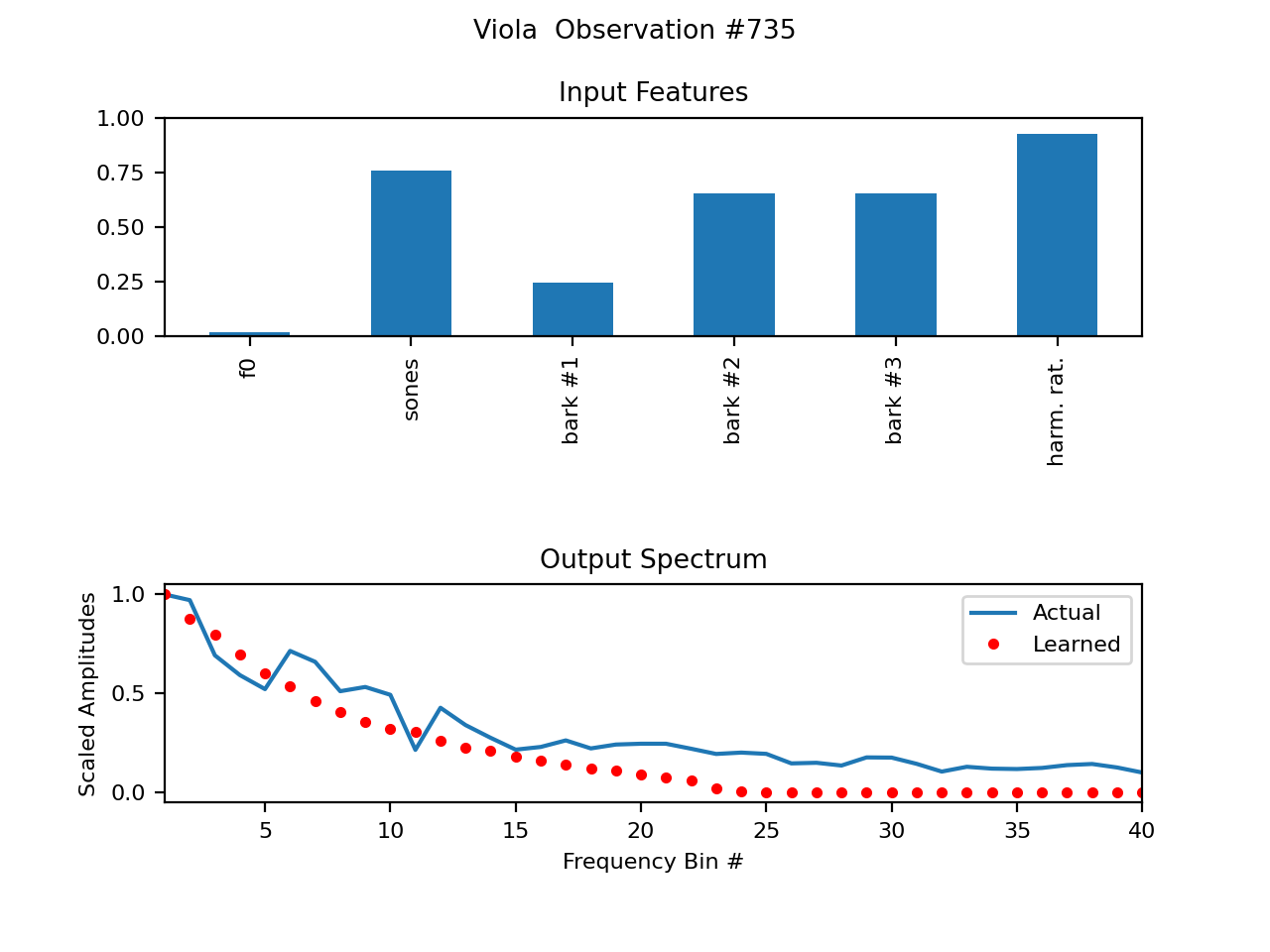
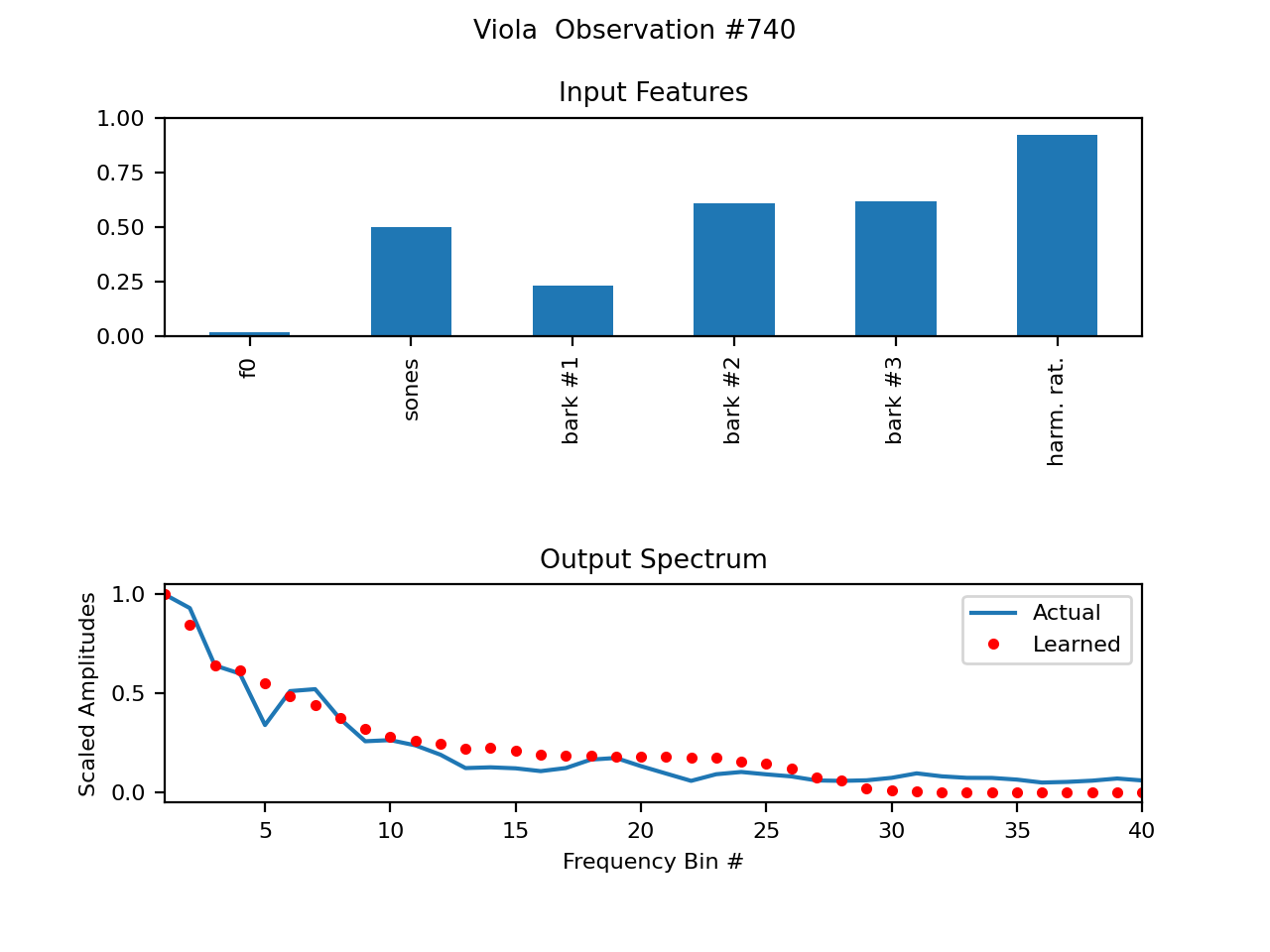
Newest version of WTIANNS
Recent version of WTIANNS, non-musical example (no amplitude envelope)
Early version of WTIANNS. Since then, the data labeling, training, and sound synthesis quality have all improved.